
How AI might shape society and what Superintelligence might look like

In my last post, I gave some assigned reading on Leopold Aschenbrenner’s paper “Situational Awareness”. Those who had the time to read it will be able to read this post with better context.
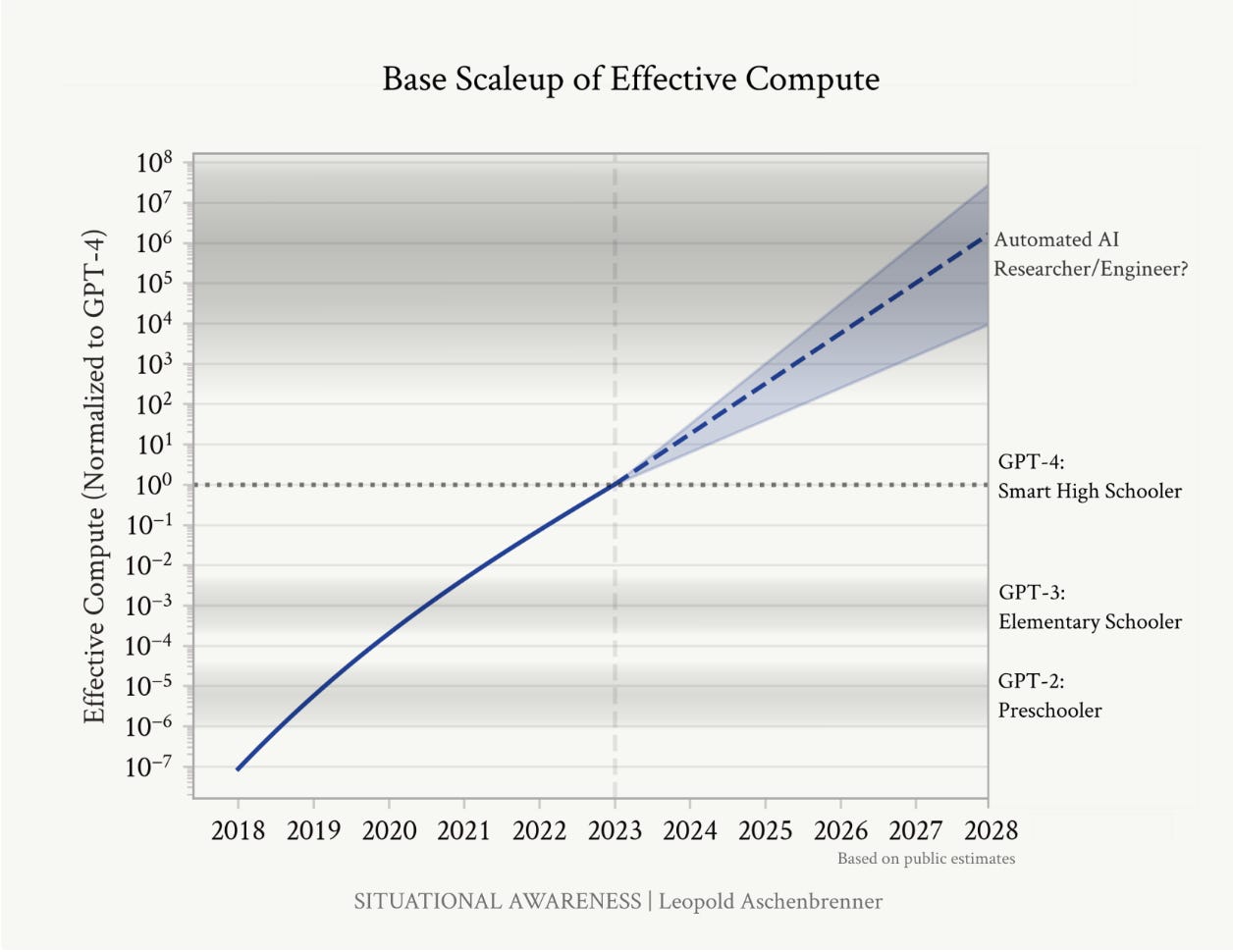
Leopold’s estimates of how model intelligence and efficiency have been tracking well since he wrote the paper two years ago. In the quote below, OOM means Orders of Magnitude, or a 10x improvement
Over the 4 years following GPT-4, we should expect the trend to continue: on average 0.5 OOMs/yr of compute efficiency, i.e. ~2 OOMs of gains compared to GPT-4 by 2027. While compute efficiencies will become harder to find as we pick the low-hanging fruit, AI lab investments in money and talent to find new algorithmic improvements are growing rapidly. (The publicly-inferable inference cost efficiencies, at least, don’t seem to have slowed down at all.) On the high end, we could even see more fundamental, Transformer-like breakthroughs with even bigger gains.
Today, model intelligence falls around that of a PhD in some areas and that of an untrained college graduate in others, falling inside the cone of outcomes that he predicted (below). We are not quite at the level of an automated AI researcher/engineer yet. There are still seven more months to go in 2026 though.
One important concept Aschenbrenner introduces is the idea that models are intentionally “hobbled” by AI labs and users. What he means by this is that AI models were restricted (until a year ago) from having access to tools like email and other software, our chat histories, smartphones, and our computer files. However, this is quickly changing - Perplexity Computer, Claude, and Manus now give AI the ability to navigate your computer using a mouse, APIs and MCPs allow models to connect to email and other software, and there are even services that allow agents to spend from a credit card or crypto wallet.
Despite AI being less hobbled today, many people are reluctant to give AI full access to our digital lives because of two concerns - trust and security. People don’t trust that AI won’t do something stupid like delete our entire email inbox or code base, and people are still afraid that AI agents create a cybersecurity attack vector in the form of injection prompting and other methods. As models and model harnesses (such as Openclaw and Claude Code) improve, these concerns should hopefully recede and go a long way in unhobbling AI.
Perhaps the most significant way AI is hobbled today is the lack of a physical embodiment and the inability to interact with the 3D world. Again, this will likely change as robotics improve and models get trained on the physical world.
Aschenbrenner believes that the next step change in the power of AI will come with recursive self-improvement - where the model becomes its own AI researcher and can discover new algorithmic efficiencies and train its successor model. Both Dario Amodei and Sam Altman have revealed that AI today contributes to training and research, but it is nowhere close to being autonomous.
Once we get AGI, we won’t just have one AGI. I’ll walk through the numbers later, but: given inference GPU fleets by then, we’ll likely be able to run many millions of them (perhaps 100 million human-equivalents, and soon after at 10x+ human speed). Even if they can’t yet walk around the office or make coffee, they will be able to do ML research on a computer. Rather than a few hundred researchers and engineers at a leading AI lab, we’d have more than 100,000x that—furiously working on algorithmic breakthroughs, day and night. Yes, recursive self-improvement, but no sci-fi required; they would need only to accelerate the existing trendlines of algorithmic progress (currently at ~0.5 OOMs/year).
Automated AI research could probably compress a humandecade of algorithmic progress into less than a year (and that seems conservative). That’d be 5+ OOMs, another GPT-2-to GPT-4-sized jump, on top of AGI—a qualitative jump like that from a preschooler to a smart high schooler, on top of AI systems already as smart as expert AI researchers/engineers.
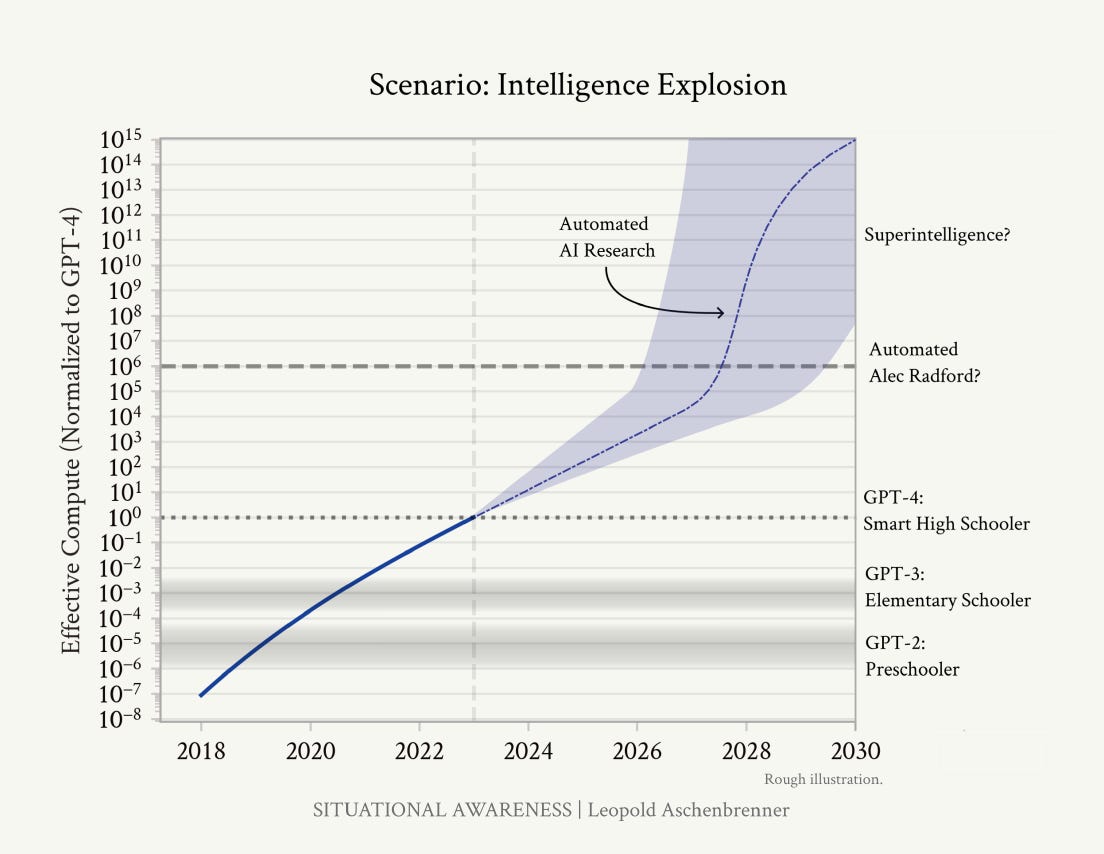
As compute, algorithmic improvements, and recursive self-improvement continue to scale and as AI become unhobbled, we will inevitably create a form of Superintelligence within the next five years. Superintelligence that is given the freedom to deploy capital and coordinate agents and humans into action may have the ability to solve some of humankind’s biggest problems, such as curing cancer, fixing climate change, and developing fusion energy. However, the more powerful AI gets, the more extreme its dual-use (civilian vs military) abilities will be. We are already seeing this with Anthropic’s Mythos, a model so powerful at coding that it can also uncover previously unknown software vulnerabilities. In response, Anthropic launched Project Glasswing, giving a select group of corporations and government agencies early access to Mythos to patch their systems while delaying the model’s broader release by six months.
I would not be surprised if access to Mythos requires KYC and other security protocols that both restrict access by high‑risk users and allow Anthropic to ban accounts or monitor how the model is being used. Each subsequent model release will come with greater capabilities but also tighter restrictions on who can access it. Eventually, Superintelligence will likely become powerful enough to serve as an offensive weapon, capable of subjugating populations and toppling governments. In that world, frontier models would probably be licensed only to a narrow set of corporations and governments, while everyone else is restricted to second‑ and third‑tier systems.
When this happens, frontier AI labs will become the powerful gatekeepers of Superintelligence and will have extreme pricing power. The corporations with access to Superintelligence will have an incredible edge over the rest of their industry in technological advancement, dividing the world into Superintelligence haves and have-nots. Investors will need to be invested in the frontier labs (Anthropic, OpenAI, Google) and the corporations with access. Google stands out as the one company that has the AI expertise and compute to stay at the frontier and the capital to leverage Superintelligence to create enormous value.
In the near term, AI is putting labor through a kind of J‑curve. On the left side of the curve, we get a burst of efficiency: individual workers become more productive, and companies can either reduce headcount or do far more with the same number of people. At the same time, many existing business models are being quietly hollowed out by AI - legal research, basic software implementation, copywriting, customer support, and parts of finance and consulting are already feeling this pressure. Entire categories of jobs get automated faster than new ones appear, and the overall vibe in many industries is anxiety and retrenchment. Eventually, though, if Leopold is right about the pace of progress, we hit the upward hockey stick part of the curve. Models begin to unlock genuinely new discoveries, products, and even whole industries.
On that upslope, I expect more of us to end up “working for AI” in a very literal sense. As agents become more competent and trustworthy, humans will rationally choose to offload more decision‑making and execution to them. In many cases, AI will be seen as the superior decision maker, because humans in organizations are fallible and subject to politics, ego, and emotions. AI will benefit from greater context drawn from a deep well of organizational and industry data.
Humans, agents, and machines will all become resources managed side by side in AI-led organizations. There is something unsettling about that framing, but there is also a real upside: if you believe Leopold’s numbers, a civilization with hundreds of millions of expert‑level AI researchers and operators should be able to compress decades of scientific and technological progress into a handful of years.
To put this into a clearer example - let’s say humans use Superintelligence to cure cancer. The AI would design the molecules and therapeutics but would need to enlist human scientists and robots to perform the testing. The AI can create a blueprint to manufacture the therapeutics at scale and create a business plan to balance profit while getting the medicine to the most people possible. However, it will be up to humans and agents to execute on that plan.
Aschenbrenner sees two scenarios where Superintelligence goes badly wrong for humankind:
Misaligned superintelligence in the wild.
If a misaligned system with the ability to copy itself and operate across networks is ever “let loose,” we may end up with an adversarial, superhuman agent pitted directly against humanity. In Aschenbrenner’s terms, this is the nightmare scenario where the intelligence explosion happens without adequate superalignment and superdefense.Weaponized superintelligence by states or rogue actors.
Even if we solve alignment “well enough” for commercial use, the same capabilities will be immensely attractive to states, militaries, and non‑state actors as offensive tools. Superintelligence tightly integrated into cyber operations, drone swarms, information warfare, and autonomous weapons will give decisive military advantages - and, in the wrong hands, could be used to subjugate populations or destabilize entire regions.
What worries me is that we are still under‑invested in both AI security (who gets access to the most capable models and weights) and AI safety (whether those systems actually do what we intend). Aschenbrenner is blunt on this: frontier labs today have security that is barely better than a normal startup, while they are sitting on what he calls “the most important national defense secrets” of this century. If that is even directionally right, we are on course to proliferate the most powerful technology ever built to a long tail of actors who should absolutely not have it.
Who should hold the keys?
Aschenbrenner’s view is that, for all its flaws, the “free world” led by the US is the least bad custodian of superintelligence: better Washington than Beijing, Moscow, or Tehran. I agree with him that superintelligence in the hands of the CCP or other fully authoritarian regimes would be incredibly dangerous. A surveillance state armed with systems that can read everyone’s data, predict dissent, and orchestrate repression with machine precision is about as bad as it gets.
Where I part ways with him is in treating the US government as a reliably “safe” steward. If anything, the US military has been responsible for more violence than any other nation-state over the last half century. The American political system is already extremely polarized, and that polarization is throwing up leaders with more extreme views and fewer guardrails. The same technology that could defend liberal democracies could just as easily be turned inward: weaponized for mass surveillance, automated censorship, targeted harassment, and politicized law enforcement. Superintelligence embedded in an unstable US political environment is not only dangerous for enemies of the US, but also detrimental to the groups within the US who fall out of favor with whoever is in power.
This is why who gets access to frontier models matters so much. If, as seems likely, we end up in a world where only a small set of governments and corporations are licensed to run the most powerful systems, we are implicitly deciding which coalitions of humans get to steer a civilization‑scale optimization process. That choice is not just about innovation and GDP; it is about the distribution of power - both within societies and between them - for the rest of the century.
Disclaimer: The content of this newsletter is provided for informational and educational purposes only and should not be construed as professional financial advice, investment recommendations, or a solicitation to buy or sell any securities or instruments. The newsletter is not a trade signaling service and the author strongly discourages readers from following his trades without experience and doing research on those markets. The author of this newsletter is not a registered investment advisor or financial planner. The information presented on this newsletter is based on his own research and experience, and should not be considered as personalized investment advice. Any investment or trading decisions you make based on the content of this newsletter are at your own risk. Past performance is not indicative of future results. All investments carry the risk of loss, and there is no guarantee that any trade or strategy discussed in this newsletter will be profitable or suitable for your specific situation. The author of this newsletter disclaims any and all liability relating to any actions taken or not taken based on the content of this newsletter. The author of this newsletter is not responsible for any losses, damages, or liabilities that may arise from the use or misuse of the information provided.
Nice summary, and I think your point at the end is also what a lot of people think when they hear Alexandr Wang or Aschenbrenner say "I trust the US government to handle this correctly! Elections = ethical and accountable officials". In fact I think some authoritarian states are structurally more accountable to their population in some ways.
I would point out that people like to ask "who gets control of superintelligence?" but the premise is the user has to be able to control and trust it in the first place, which is exactly the agent adoption problem. Giving unlimited access to your email and credit card is frankly insanity at this point in time. If superintelligence helps you build weapons for example, whatever it outputs has to be something the user understands and trusts to kill only who they want it to.
I did olympiad math and studied lots of very abstract math when I was young, worked on a lot of industry deep learning applications since circa 2016, and I would say that in my experience there is a sort of qualitative gap between being able to do math and being able to model things. It takes more brain power for a human to do advanced math but not everyone who is good at math comes up with good ideas for modelling (I've seen this with friends from top math PhD programs, though I would say most mathematicians are good at modelling because math already requires asking lots of questions). A lot of this is perhaps just real world context that is very messy.
It doesn't feel like AI has crossed that gap yet, but I don't rule out that it imminently could (I think at least a few more years though). When I saw what Deepmind was working on 10 years ago it hit me that humans really aren't as smart as we think. I thought we would have till ~2040 back in 2020, but I think everyone with a nice job should be prepared to be humbled and lose their job pretty soon. If your identity and pride revolves around your work, you need soul searching on top of financial preparation.
The one thing to note however is that this exponential increase in compute is physically constrained. The non-linear speedup has mainly come from bandwidth increases (because the GPUs of the past had nowhere near enough memory to store trillions of parameters, so you had to shuttle data over relatively big distances). "Thinking" is inherently a non-parallel kind of scaling (can have multiple models "talking to each other" but they still block each other). It is hard to find 10x more natural gas to pipe to one location or 10x more copper wire. Even if superintelligence can improve itself, scaling compute in non-parallelizable areas is an uphill climb.
The run in SNDK for example makes a lot of sense given they want to build stacked NAND flash. You can store a core model that is well trained for logical reasoning and language on HBF. It's both cheaper and more dense with only a small read speed penalty. However these kinds of improvements sort of become harder to find going forward. At some point, it will be obvious 10x the compute just doesn't deliver 10x the economic value anymore, and finding that point will be the key to trading this run successfully.
I think this is why open-weight models matter so much. The risk isn't just a misaligned AI — it's an aligned-to-the-wrong-people AI. Whether that's Silicon Valley elites, policymakers in DC, or authoritarian regimes, concentrating control over Superintelligence in any single group's hands is a civilizational risk in itself. Open-weight models aren't perfect, but they distribute the ability to audit, fork, and contest AI systems broadly — acting as a kind of checks-and-balances for a technology that could otherwise become the ultimate lever of power. The alternative is essentially handing a monopoly on the future to whoever gets there first.